

Photo by Héctor J. Rivas on Unsplash
A Comprehensive Guide to Image Alignment with Python and OpenCV





Table of contents
- What is Image Alignment?
- Importance of Image Alignment
- Common Scenarios Requiring Image Alignment
- Types of Image Alignment
- Affine Transformation
- Translation, Rotation, Scaling
- Homography Transformation
- Key Feature Identification
- What are Key Features?
- Role in image alignment
- Overview of ORB (Oriented FAST and Rotated BRIEF)
- OpenCV in Image Alignment
- Significance in Computer Vision and Image Processing
- Code Overview and Implementation Details
- Code Walkthrough
- Implementation
- Results
- Conclusion
- References
In the vast realm of computer vision and image processing, the precise alignment of images stands as a pivotal task with far-reaching implications. Image alignment, often considered the cornerstone of numerous applications, involves the intricate process of harmonizing the spatial arrangement of two or more images. This alignment, achieved through a combination of mathematical transformations and feature matching, unlocks a myriad of possibilities, from panoramic image stitching to object recognition in computer vision.
Understanding image alignment requires a blend of theoretical knowledge and hands-on experience with practical implementations. In this blog post, we embark on an exploration of image alignment techniques using Python and OpenCV, unraveling the underlying concepts and demystifying the code that brings these theories to life.
What is Image Alignment?
Image alignment is the process of finding the spatial mapping between elements in one image and matching them with elements in another image. It involves transforming one image to align with another image, typically by adjusting factors such as rotation, translation, and scale. Image registration, on the other hand, is a broader term that includes image alignment but also encompasses other tasks such as transforming data from different sources into a common coordinate system
Importance of Image Alignment
Image alignment plays a crucial role in enhancing image quality and facilitating effective comparison and analysis in various fields.
Improving Image Quality: Image alignment helps in improving the overall quality of images by reducing distortions, misalignments, and artifacts that may occur during image acquisition or processing. By aligning multiple images, such as in panorama construction or aerial image stitching, the final composite image appears seamless and visually appealing.
Enhancing Comparison and Analysis: Proper image alignment enables accurate comparison and analysis of images, which is essential in various fields such as remote sensing, surveillance, object recognition, and scientific research. Aligned images allow for consistent measurements, feature extraction, and pattern recognition across different images or frames. In object recognition and tracking applications, aligned images help in detecting objects accurately by ensuring that features are correctly matched between frames.
Common Scenarios Requiring Image Alignment
Image alignment plays a pivotal role in various scenarios, enhancing the quality and applicability of digital imagery. Common situations where image alignment is crucial include:
Aerial Image Stitching
Medical Image Registration
Panorama Construction
Object Recognition and Tracking
Video Stabilization
Types of Image Alignment
Image alignment is a critical process in computer vision that involves bringing two or more images into a consistent spatial relationship. Different scenarios may require distinct types of image alignment techniques. Here are some common types:
Affine Transformation
An affine transformation is a geometric transformation that preserves collinearity (points lying on a line initially still lie on a line after transformation) and ratios of distances between points on a line. It maintains parallelism but not necessarily Euclidean distances and angles.
![]()
Translation, Rotation, Scaling
Translation, rotation, and scaling are fundamental transformations used in various applications like computer graphics, image processing, and geometric modeling. Here is a breakdown of each transformation:
Translation
Definition: Translation changes the origin (0,0 point) of the canvas's coordinate system. It involves moving the entire coordinate system to a new location specified by calling the
translate(x,y)method.Usage: It is commonly used to reposition objects without altering their shape or orientation.
Example: Redrawing a path at a new location without changing its shape by translating the canvas's origin.
Rotation
Definition: Rotation involves spinning the drawing surface around a specified point (usually the origin) by calling the
rotate(angle)method.Usage: It is used to rotate objects around a fixed point.
Example: Rotating a shape around its center at a specific angle.
Scaling
Definition: Scaling changes the size of objects by expanding or contracting them along the X and Y axes. It is done by calling the
scale(xScale, yScale)method.Usage: Scaling is used to resize objects while maintaining their proportions.
Example: Enlarging or shrinking an object without changing its shape.
![]()
Homography Transformation
A homography transformation, also known as a perspective transformation, is a linear transformation used in computer graphics and computer vision to shift from one view to another view of the same scene by multiplying the homography matrix with points in one view to find their corresponding locations in another view. This transformation is crucial for applications like image rectification, image registration, camera motion estimation between images, navigation, and inserting 3D objects into images or videos with correct perspective.
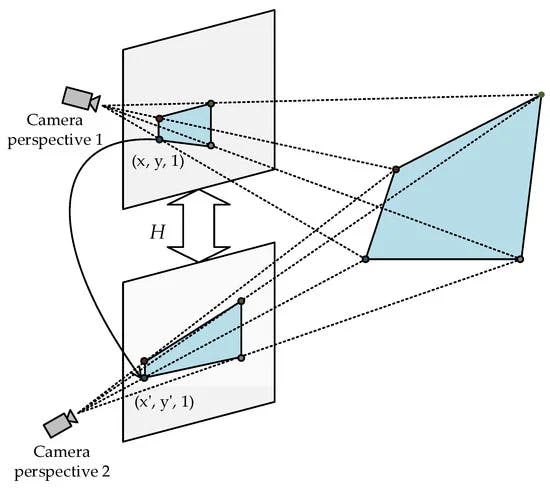
RANSAC (Random Sample Consensus): It is an iterative method used to estimate parameters of a mathematical model from a set of observed data that contains outliers.RANSAC plays a crucial role in finding a robust homography matrix by iteratively estimating the homography parameters from a set of correspondences between images, where outliers can significantly affect the accuracy of the estimation.
Key Feature Identification
What are Key Features?
Key features, often referred to as keypoints, are specific points or regions in an image that are distinctive and robust against variations like changes in viewpoint, illumination, scale, and noise. Along with keypoints, descriptors are associated with each keypoint to encode information about its local neighborhood, enabling comparison and matching between keypoints in different images.

Role in image alignment
Key features play a crucial role in image alignment by providing a set of distinctive points that can be matched between images to estimate the transformation needed to align them accurately. By identifying and matching keypoints along with their descriptors, algorithms can determine the spatial relationship between images and compute the transformation parameters required for alignment.

Overview of ORB (Oriented FAST and Rotated BRIEF)
ORB (Oriented FAST and Rotated BRIEF) is a feature detection and description algorithm that combines the FAST keypoint detector and BRIEF descriptor with enhancements to improve performance. In the alignment process, ORB plays a crucial role in detecting features or corners across an input pyramid and computing descriptors for each feature, providing coordinates and bitstring descriptors for features in the highest resolution base image of the input.

OpenCV in Image Alignment
OpenCV, short for Open Source Computer Vision Library, is a powerful open-source computer vision and machine learning software library. It provides a wide range of tools and functions for real-time computer vision applications, image processing, and machine learning algorithms. OpenCV supports various programming languages such as C++, Python, and Java, making it accessible to a broad community of developers and researchers.
Significance in Computer Vision and Image Processing
OpenCV plays a crucial role in computer vision and image processing due to its extensive collection of functions for tasks like image manipulation, feature detection, object recognition, camera calibration, and image alignment. It offers efficient implementations of algorithms for image alignment techniques such as feature-based matching, homography estimation, RANSAC for outlier rejection, and geometric transformations (affine, perspective).

OpenCV's robustness and performance make it a popular choice for both research and industrial applications in fields like robotics, autonomous vehicles, medical imaging, surveillance systems, and more. In the context of image alignment specifically, OpenCV provides a comprehensive set of tools and functions that simplify the process of registering images accurately. Its support for various transformation models and optimization algorithms makes it an invaluable resource for tasks requiring precise alignment of images in computer vision applications.
Code Overview and Implementation Details
For a practical demonstration and hands-on experience with OpenCV-based image alignment, you can explore the code implementation available on GitHub and Google Colab.
GitHub Repository: Visit ImageAlignment-OPENCV to access the source code. You'll find a detailed implementation using OpenCV, allowing you to delve into the specifics of image alignment.
Google Colab Notebook: Alternatively, you can explore the code interactively on Google Colab. Access the notebook directly by clicking here. This provides a convenient platform for running the code and experimenting with different parameters.
Code Walkthrough
import cv2
import numpy as np
import matplotlib.pyplot as plt
def align_images(ref_filename, im_filename):
# Read reference image
print("Reading reference image:", ref_filename)
im1 = cv2.imread(ref_filename, cv2.IMREAD_COLOR)
im1 = cv2.cvtColor(im1, cv2.COLOR_BGR2RGB)
# Read image to be aligned
print("Reading image to align:", im_filename)
im2 = cv2.imread(im_filename, cv2.IMREAD_COLOR)
im2 = cv2.cvtColor(im2, cv2.COLOR_BGR2RGB)
# Convert images to grayscale
im1_gray = cv2.cvtColor(im1, cv2.COLOR_BGR2GRAY)
im2_gray = cv2.cvtColor(im2, cv2.COLOR_BGR2GRAY)
# Detect ORB features and compute descriptors
MAX_NUM_FEATURES = 500
orb = cv2.ORB_create(MAX_NUM_FEATURES)
keypoints1, descriptors1 = orb.detectAndCompute(im1_gray, None)
keypoints2, descriptors2 = orb.detectAndCompute(im2_gray, None)
# Match features
matcher = cv2.DescriptorMatcher_create(cv2.DESCRIPTOR_MATCHER_BRUTEFORCE_HAMMING)
matches = matcher.match(descriptors1, descriptors2, None)
# Sort matches by score
matches = sorted(matches, key=lambda x: x.distance)
# Remove not so good matches
num_good_matches = int(len(matches) * 0.1)
matches = matches[:num_good_matches]
# Extract location of good matches
points1 = np.zeros((len(matches), 2), dtype=np.float32)
points2 = np.zeros((len(matches), 2), dtype=np.float32)
for i, match in enumerate(matches):
points1[i, :] = keypoints1[match.queryIdx].pt
points2[i, :] = keypoints2[match.trainIdx].pt
# Find homography
retval = cv2.findHomography(points2, points1, cv2.RANSAC)
h, mask = retval[0], retval[1]
# Use homography to warp image
height, width, channels = im1.shape
im2_reg = cv2.warpPerspective(im2, h, (width, height))
# Display key features in another window
im1_display = cv2.drawKeypoints(im1, keypoints1, outImage=np.array([]), color=(255, 0, 0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
im2_display = cv2.drawKeypoints(im2, keypoints2, outImage=np.array([]), color=(255, 0, 0),
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
plt.figure(figsize=[20, 10])
plt.subplot(121); plt.imshow(im1_display); plt.axis('off'); plt.title("Reference Image Key Features")
plt.subplot(122); plt.imshow(im2_display); plt.axis('off'); plt.title("Test Image Key Features")
plt.show()
# Display results
plt.figure(figsize=[20, 10])
plt.subplot(131); plt.imshow(im1); plt.axis('off'); plt.title("Reference Image")
plt.subplot(132); plt.imshow(im2); plt.axis('off'); plt.title("Test Image")
plt.subplot(133); plt.imshow(im2_reg); plt.axis('off'); plt.title("Aligned Image")
plt.show()
if __name__ == "__main__":
reference_filename = "reference_imgae.jpg"
image_filename = "test_image.jpg"
align_images(reference_filename, image_filename)
Implementation
The provided Python script uses the OpenCV library to perform image alignment between a reference image and a test image. It employs the ORB feature detection method to identify key points and descriptors in grayscale versions of the images. The script then matches these features and uses RANSAC to find a robust homography matrix. This matrix is applied to warp the test image and align it with the reference image. The script also visualizes key features and displays the original, test, and aligned images using matplotlib. Finally, it reads images from specified file paths and demonstrates the image alignment process.
Results

Conclusion
In conclusion, image alignment is a crucial technique in computer vision, enabling the precise matching and registration of images. The presented code showcases the power of OpenCV, utilizing the ORB feature detection and RANSAC for robust alignment.